
想法来源观看 二叉树树 的视频 【B站评论惊现诈骗链接!!!这是怎么做的????】 后,想要更深入地了解这个现象,从而有了这期博客。
引言:关于“诈骗链接”
在浏览 BiliBili 评论区时,常会发现 B 站的视频链接以标题的形式显现,如下图:
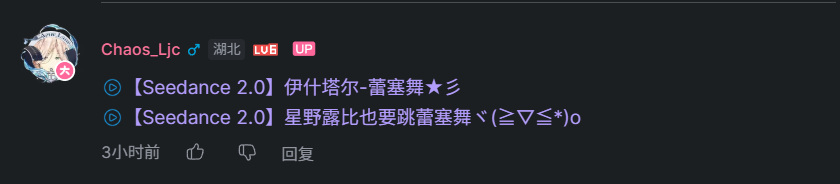
但会遇到点击的视频标题与跳转到的视频页标题不一致的现象,也就是我们所说的诈骗链接。具体情形可以从二叉树树的视频中看到。
他也给出了制作这样的“诈骗链接”的方法:
- 模板:
https://www.bilibili.com/video/BV_X/../BV_Y BV_X替换为显示标题的BV号,BV_Y替换为跳转的BV号- 使用任意B站短链接生成器(例如:B站短链接生成工具)生成短链接(符合
^https://b23\.tv/[A-Za-z0-9]{7}$),并发布于B站评论区
以及漏洞的剖析:前端在渲染链接时,读取第一个合法 BV 号获取标题,在这里就是 BV_X 对应的标题,而点击会去跳转到原始的 url(包含/../),从而实际跳转到 https://www.bilibili.com/video/BV_Y。
这样的解释固然合乎道理,但于我而言,我还想要了解更多——为什么会造成这样的结果呢?
下文就记录了我的一些探索的所得。
📺关于 B 站评论区链接的渲染
据我观察,在B站发布评论时,输入文本是 B 站相关链接 则会被渲染为超链接;其中,若链接指向的是某个 B 站视频,则会被渲染为对应视频标题。当然,B站评论区还会存在其他类型的超链接,比如:跳转站外的蓝链(广告…)、BV号、av号、@用户昵称 …… 而其中BV号、av号等也会替换为其对应的title进行超链接的渲染。
总结该现象:
- 有的链接直接显示原始 URL;
- 有的链接显示成更友好的标题(例如视频标题);
- 同一条评论里,可能两种显示方式同时出现。
从根本来说,前端 HTML 中,创建超链接 通过 <a>标签实现,这里同样如此。问题在于:如何确认评论中某段文本是超链接?超链接的url如何得来?以及,如何确认渲染内容不是url而是对应视频标题?该视频标题如何得来?
观察网络请求,或查看文档可得:
-
GET请求https://api.bilibili.com/x/v2/reply/wbi/main懒加载获取评论区明细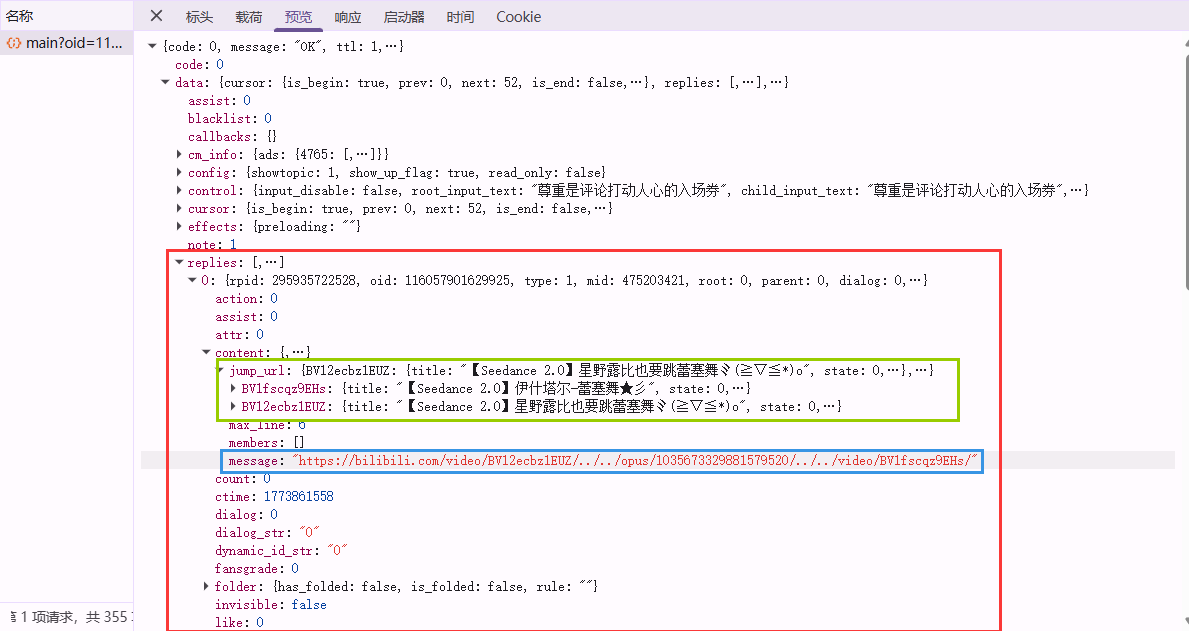
-
评论主体通常在
content中,常见字段包括:message:用户输入的原始文本;jump_url:可跳转片段的映射表(键通常是某个可识别 token,如BV...);members:@用户的映射;emote:表情映射;pictures: 图片映射;
一个典型的
jump_url结构是:{"BV12ecbz1EUZ": {"title": "【Seedance 2.0】星野露比也要跳蕾塞舞ヾ(≧▽≦*)o","state": 0,...},"BV1fscqz9EHs": {"title": "【Seedance 2.0】伊什塔尔-蕾塞舞★彡","state": 0,...}}注意:
jump_url的 key 是否与文本切片后的内容“精确一致”,决定了能否显示标题。
简单地浏览B站前端关于comment的js代码,对于整体渲染的流程应该可以概括为 4 步:
-
拉取评论数据
前端请求评论接口,得到replies列表及每条content。 -
文本解析为富文本节点
核心解析函数会把message切成片段,并生成节点数组(例如span、a、img)。 -
节点渲染为 HTML
富文本组件把节点数组转换成真实 DOM,例如:<a href="..." data-type="link">...</a><span>...</span>
Hv = function (t, e, n, i, r) {return {tag: "a",style: i,dataset: r || {type: "link"},a: {text: uv(e || "网页链接"),href: t,icon: n,target: "_blank"}}}上述是源码中构造链接节点的一个逻辑,可见:超链接在数据层就是一个
tag: "a"节点,dataset.type默认是link。 -
点击事件分流
点击链接后,根据data-type(link/search/goods/seek等)执行不同逻辑和埋点。
而其中最关键的机制是:
先“切片”,再“按片段匹配 jump_url”
1. 先做分片
解析器会按照多类规则切片,包括但不限于:
- URL(白名单/正则);
AV/BV/CV/EP/SS;@用户名;- 时间点(如
01:23); - 普通文本;
- …
源码中有这样的一些正则匹配(已添加注释):
// 匹配B站AV号:匹配以AV/av/Av/aV开头,后面跟一串数字的格式(如AV123456、av7890)p = new RegExp("(AV|av|Av|aV)[0-9]+", "ug"),
// 匹配B站BV号:B站视频的新标识符,规则是BV/bv/Bv/bV开头,// 接着是1,然后跟9个字符(范围:1-9、A-N、P-Z、a-k、m-z,排除了O和l等易混淆字符)f = new RegExp("(BV|bv|Bv|bV)1[1-9A-NP-Za-km-z]{9}", "ug"),
// 匹配B站CV号/专栏移动端链接:// 第一种:CV/cv开头+数字(如CV12345);第二种:mobile/开头+数字(移动端专栏链接)m = new RegExp("((CV|cv)[0-9]+|(mobile/[0-9]+))", "ug"),
// 匹配B站EP号:番剧的剧集编号,EP/ep/Ep/eP开头+数字(如EP12、ep34)y = new RegExp("(EP|ep|Ep|eP)[0-9]+", "ug"),
// 匹配B站SS号:番剧的季度编号,SS/ss/Ss/sS开头+数字(如SS1、ss2)b = new RegExp("(SS|ss|Ss|sS)[0-9]+", "ug"),
// 匹配中括号包裹的任意Unicode字符:// 匹配[]内包含的所有合法Unicode字符(涵盖基本多文种平面和扩展平面字符),// 包括常见字符、emoji、生僻字等,是B站评论区常见的内容包裹格式w = /\[(?:[\0-'\+-Z\\\^-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDBFF](?![\uDC00-\uDFFF])|(?:[^\uD800-\uDBFF]|^)[\uDC00-\uDFFF])+\]/g,
// 匹配B站及相关域名:// 包含bilibili主域名(com/tv/cn)、衍生域名(esheep、biligame、b23.tv等)、// 合作/关联域名(苏宁sugs、人民网、考拉、央视等),$v和Gv是外部变量(可能是协议/参数前缀)x = new RegExp("".concat($v, "?([a-z0-9A-Z-]{1,15}.)?(bilibili\\.(com|tv|cn)|esheep\\.(com|cn|net)|biligame\\.(com|cn|net)|(bilibiliyoo|im9)\\.com|biliapi\\.net|b23\\.tv|bili22\\.cn|bili33\\.cn|bili23\\.cn|bili2233\\.cn|(sugs\\.suning\\.com)|jueze2021\\.peopleapp\\.com|kaola\\.com|bigfun\\.cn|mcbbs\\.net|mp\\.weixin\\.qq\\.com|static\\.cdsb\\.com|bjnews\\.com\\.cn|720yun\\.com|\\.cctv\\.com)($|/|)").concat(Gv), "ug"),
// 匹配B站视频链接:// 包含bilibili主站/video路径、b23.tv等短链接,匹配AV号或BV号格式的视频链接k = new RegExp("".concat($v, "?(((uat-)?www\\.bilibili\\.com)|(b23\\.tv|bili22\\.cn|bili33\\.cn|bili23\\.cn|bili2233\\.cn))(/video)?/((av[0-9]+)|((BV)1[1-9A-NP-Za-km-z]{9}))($|/|)").concat(Gv), "ug"),
// 匹配B站番剧播放链接:// 包含bangumi/play路径,匹配EP号或SS号的番剧播放链接A = new RegExp("".concat($v, "?(((uat-)?www\\.bilibili\\.com/bangumi/(play/|media/)|(b23\\.tv|bili22\\.cn|bili33\\.cn|bili23\\.cn|bili2233.cn)/)(ss|ep)[0-9]+)($|/|)").concat(Gv), "ug"),
// 匹配B站专栏/文章链接:// 包含read路径,匹配CV号、native?id、app/、mobile/等格式的专栏链接_ = new RegExp("".concat($v, "?(uat-)?www\\.bilibili\\.com/read/((cv[0-9]+)|(native?id=[0-9]+)|(app/[0-9]+)|(native/[0-9]+)|(mobile/[0-9]+))($|/|)").concat(Gv), "ug"),
// 匹配时间戳格式:// 支持 数字#数字:数字:数字(如1#12:34:56)、数字:数字:数字(如12:34:56)、数字:数字:数字(中文冒号)// 最少匹配 数字:数字:数字(如1:2:3),是视频评论区常见的时间点格式E = /(\d+#)?(\d+(:|:)){1,2}\d\d/g2. 对每个“候选片段”再检查 jump_url
- 命中
jump_url[片段]:用对应信息组装链接节点; - 未命中:走默认链接逻辑(通常保留原文本显示)
3. 标题显示规则
当命中 jump_url 时,显示文案通常是:
title || 原片段文本
即:有标题就显示标题,否则退回原文本。
这个应该是 jump_url 命中后的标题选择的函数:
L = function (t, e) { var r = e.pc_url , o = e.app_url_schema , a = e.title , s = e.prefix_icon , l = e.match_once , c = e.icon_position , u = e.extra; if (l && N[t]) return Wv(t); N[t] = !0; var d = 1 === c , h = ""; if (r ? h = dv(r) : (C(x), x.test(t) ? (h = dv(t, !0), i && (C(k), k.test(h) && (h = Mv(h, i)))) : (C(f), C(p), C(m), f.test(t) ? (h = Ch({ bvid: t }), i && (h = Mv(h, i))) : p.test(t) ? (h = Ch({ avid: Eu(t) }), i && (h = Mv(h, i))) : m.test(t) ? (h = Th(Eu(t)), i && (h = Mv(h, i))) : h = function (t) { if (t.startsWith("http")) { var e = t.match(/www.bilibili.com\/h5\/note-app\/view\?cvid=(\d+)/); return null != e && e[1] ? Th(e[1]) : t } return "" }(t))), !h) return Wv(t); var y = a || t , b = "" , g = !1 , w = ""; (null != u && u.goods_item_id || null != u && u.goods_prefetched_cache) && (g = !0, null != u && u.goods_pc_click_urls && Array.isArray(u.goods_pc_click_urls) && (w = u.goods_pc_click_urls.join(",")), C(x), x.test(t) && (b = t)); var A = g ? { type: "goods", "goods-url": w, "raw-url": b } : null != u && u.is_word_search ? { type: "search", keyword: uv(y) } : { type: "link" }; return n === Uf.DESKTOP_APP ? A = v(v({}, A), {}, { link: h }) : n === Uf.MOBILE_BROWSER && o && (A = v(v({}, A), {}, { link: o })), Hv(h, y, s, d ? { display: "inline-flex", "flex-direction": "row-reverse", "--icon-width": "0.65em", "--icon-height": "1.2em" } : { "--icon-width": "1.2em", "--icon-height": "1.2em" }, A) }简化并语义化后,关键逻辑如下:
var L = function (token, config) { var title = config.title // ...省略 url 解析 var renderText = title || token return Hv(resolvedHref, renderText, prefixIcon, style, dataset)}可见:命中时明确是 title || token,也就是“有标题显示标题、否则显示原片段文本”。
案例
上述的论述仍有不足之处,但能够分析出我们这一小节最开始的问题。就拿我们上面的截图作为案例:
-
message是:https://bilibili.com/video/BV12ecbz1EUZ/../../opus/1035673329881579520/../../video/BV1fscqz9EHs/ -
并且
jump_url里有两个键并有对应的标题:-
BV12ecbz1EUZ -
BV1fscqz9EHs
-
最终渲染应该是:
- 第一段显示原始 URL 链接:
https://bilibili.com/video/BV12ecbz1EUZ/ - 中间
../../opus/.../../../video/显示为普通文本 - 第二段
BV1fscqz9EHs显示为标题链接
与我们的实际渲染相符:

在这里为什么第一个 BV号 没有替换 title,是 jump_url 失效了吗?不然,是切片结果不同:
- 前半段先被识别为一个 URL 片段,片段文本是完整 URL,不是
BV12...本身; jump_url的 key 是BV12...,与该 URL 片段不精确相等,因此无法直接命中;- 后半段在后续分片中切出了独立 token:
BV1f...,这时与jump_url的 key 精确匹配,所以能替换成标题。
还有类似这样的:
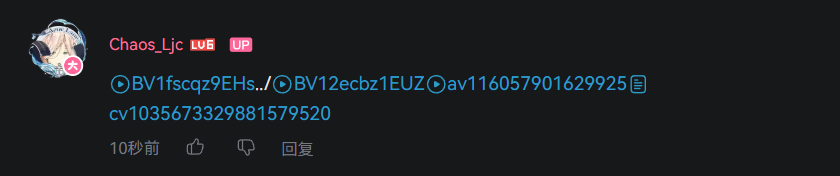
message: “https://www.bilibili.com/video/BV1fscqz9EHs/../BV12ecbz1EUZav116057901629925cv1035673329881579520”jump_url仅有一个:https://www.bilibili.com/video/BV1fscqz9EHs/../BV12ecbz1EUZav116057901629925cv1035673329881579520:{title: "【Seedance 2.0】伊什塔尔-蕾塞舞★彡", state: 0,…}
为什么没有渲染标题,就是”切片“后的无法精准匹配 jump_url 的键。当然,jump_url的计算是后端服务进行的操作,所以问题应该是后端并不是按前端切片后的数据进行 jump_url 的计算,而自有一套算jump_url的方法。而若要提高渲染 jump_url 为标题的“命中率”(:不知道这样说是否合理:),后端的 jump_url 计算方法就必须更改,比如按照前端同样的逻辑先对消息进行分片后处理是否有要显示 title 的链接,或者前后端这一块的逻辑代码一起重构以互相匹配。
那么,回到疑问:如何确认评论中某段文本是超链接?超链接的url如何得来?以及,如何确认渲染内容不是url而是对应视频标题?该视频标题如何得来?
- 通过各种正则匹配
- 输入的是全的链接自然是全的,而若是 BV 号,av 号等由于其 url 的规律性,自然可以拼接得到
- 通过后端传来的数据,核心是
jump_url的键值对
同样,B站短链是按照上述流程被渲染,如若能够匹配 jump_url 也就会被渲染为 title 的形式;而若跳转的视频标题与其不同,就造成“诈骗”;可以见得,问题就出现在这个 jump_url 计算出的 title 出错了,即:对于改模板的 url https://www.bilibili.com/video/BV_X/../BV_Y 计算出的 title 是 BV_X 的标题。
补充:流程图与对应代码锚点

- 解析入口(
qv)
function qv(t, e, n, i) { var a = t.content var s = a.message, l = a.emote, c = a.members, u = a.jump_url, d = a.vote // ... 分片与节点构造}- 命中
jump_url时优先走L()
var M = Vf(function (token) { return null != u && u[token] ? L(token, u[token]) : Hv(Sh(token), token)}, ...)- 渲染层将节点数组变成 HTML
setContents(nodes) { const html = nodes.map(/* node -> html */).join("") this.contents.innerHTML = html}- 点击事件基于
dataset分流
this.disposables.addEventListener(this.contentsElement, "click", function (e) { var n = v({}, e.target.dataset) t.dispatchEvent(new CustomEvent("text-click", { detail: n }))})🔗浅谈短链接
在说明为什么 https://www.bilibili.com/video/BV_X/../BV_Y 跳转到的是 BV_Y 之前,先来简单了解一下短链接技术。
简述
短链接是一种 URL 缩短技术,通过重定向将较长的原始链接映射到简短的地址。当用户访问短链接时,服务端返回 301/302 状态码,并在 Location 响应头中携带真实目标地址,浏览器随即跳转。
例如,以下这个冗长的 B 站链接:
https://www.bilibili.com/video/BV12ecbz1EUZ/?spm_id_from=333.999.0.0&vd_source=xxx...可以缩短为:https://b23.tv/X8QkDCP
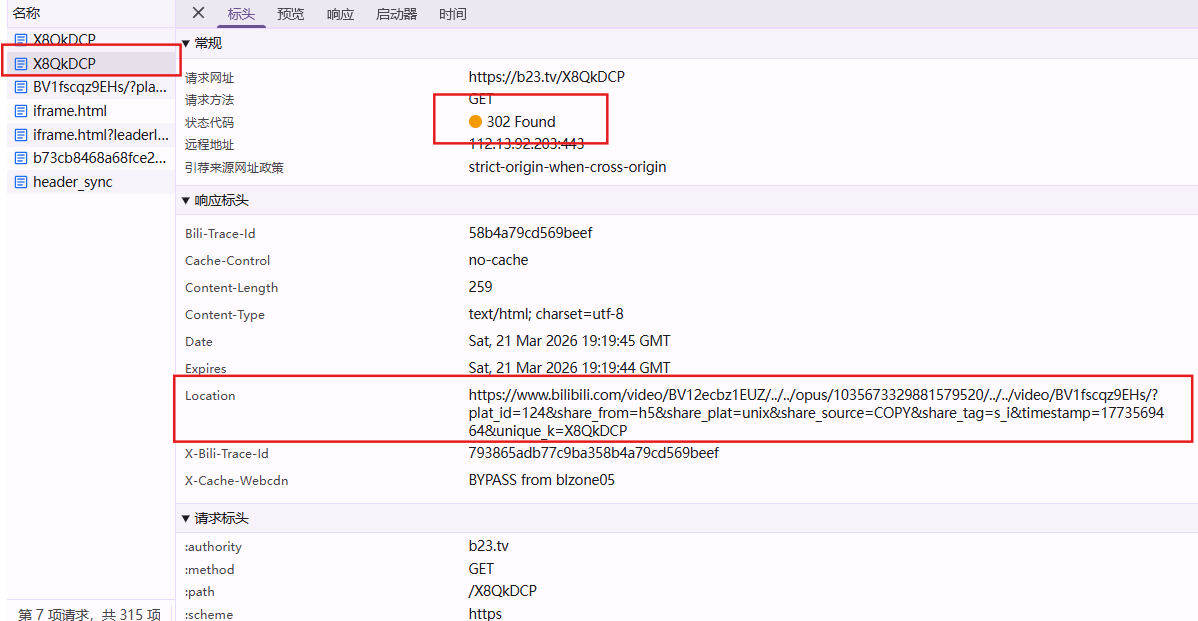
上图是短链接请求的结果,可见其核心是一次 302 重定向,Location 字段即为原始的长地址。
简单的说,短链接服务就是一个键值对数据库加上一个重定向服务器。核心为两个过程:
- 生成时:你将一个长链接(如
https://www.example.com/very/long/path?with=many¶meters)提交给服务,它返回一个短码(如abc123),并在数据库中记录短码 -> 长链接的映射 。 - 访问时:当用户点击
https://short.url/abc123,短链接服务器接收到请求,根据abc123查到对应的长链接,然后向浏览器返回一个 HTTP 301(永久重定向)或 302(临时重定向) 响应,其中Location头部就是那个原始长链接。浏览器收到后,会自动跳转过去。
b23.tv 短链生成
我们可以通过第三方的 B站短链接生成工具 来使用哔哩哔哩的短码服务,当然也可以通过 B站的API 生成 b23.tv 短链,这里给出一个脚本代码:
"""b23_generator.py - Bilibili b23.tv 短链生成工具
基于B站 API实现:接口:https://api.bilibili.com/x/share/click方法:POST功能:为视频、动态、专栏、文集、用户、课程、站内链接生成短链"""
import requestsimport jsonimport reimport sysfrom typing import Optional, Dict, Any, Union
class B23Generator: """B站短链生成器"""
# API 端点 API_URL = "https://api.bilibili.com/x/share/click"
# 不同类型内容的参数映射表(基于文档) TYPE_MAP = { "video": { "share_id": "main.ugc-video-detail.0.0.pv", "share_origin": "", "description": "视频" }, "dynamic": { "share_id": "dt.dt-detail.0.0.pv", "share_origin": "dynamic", "description": "动态/图文" }, "article": { "share_id": "read.column-detail.roof.8.click", "share_origin": "", "description": "专栏" }, "collection": { "share_id": "read.column-readlist.share.0.click", "share_origin": "", "description": "文集" }, "user": { "share_id": "main.space-total.more.0.click", "share_origin": "", "description": "用户空间" }, "course": { "share_id": "pugv.pugv-video-detail.0.0.pv", "share_origin": "vinfo_player", "description": "课程" }, "link": { "share_id": "public.webview.0.0.pv", "share_origin": "", "description": "站内链接" } }
def __init__(self, buvid: str = "b23_generator", build: int = 7710300, platform: str = "linux"): self.buvid = buvid self.build = build self.platform = platform
def _post_request(self, data: Dict[str, Any]) -> Optional[str]: headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36", "Content-Type": "application/x-www-form-urlencoded" } try: response = requests.post(self.API_URL, data=data, headers=headers, timeout=10) response.raise_for_status() result = response.json() if result.get("code") == 0 and result.get("data", {}).get("content"): content = result["data"]["content"] short_url_match = re.search(r'(https?://b23\.tv/[^\s]+)', content) if short_url_match: return short_url_match.group(1) return content else: print(f"API返回错误: {result}") return None except Exception as e: print(f"请求失败: {e}") return None
def generate_video(self, oid: Union[int, str]) -> Optional[str]: if isinstance(oid, str) and oid.startswith(('BV', 'bv')): print("注意:请传入AV号数字(aid),而非BV号") return None data = { "buvid": self.buvid, "build": self.build, "platform": self.platform, "share_channel": "COPY", "share_mode": 4, "share_id": self.TYPE_MAP["video"]["share_id"], "oid": int(oid) } print(f"正在为视频 (aid={oid}) 生成短链...") return self._post_request(data)
def generate_dynamic(self, dynamic_id: int) -> Optional[str]: data = { "buvid": self.buvid, "build": self.build, "platform": self.platform, "share_channel": "COPY", "share_mode": 4, "share_id": self.TYPE_MAP["dynamic"]["share_id"], "share_origin": self.TYPE_MAP["dynamic"]["share_origin"], "oid": dynamic_id } print(f"正在为动态 (id={dynamic_id}) 生成短链...") return self._post_request(data)
def generate_article(self, cvid: int) -> Optional[str]: data = { "buvid": self.buvid, "build": self.build, "platform": self.platform, "share_channel": "COPY", "share_mode": 4, "share_id": self.TYPE_MAP["article"]["share_id"], "oid": cvid } print(f"正在为专栏 (cvid={cvid}) 生成短链...") return self._post_request(data)
def generate_collection(self, rlid: int) -> Optional[str]: data = { "buvid": self.buvid, "build": self.build, "platform": self.platform, "share_channel": "COPY", "share_mode": 4, "share_id": self.TYPE_MAP["collection"]["share_id"], "oid": rlid } print(f"正在为文集 (rlid={rlid}) 生成短链...") return self._post_request(data)
def generate_user(self, mid: int) -> Optional[str]: data = { "buvid": self.buvid, "build": self.build, "platform": self.platform, "share_channel": "COPY", "share_mode": 4, "share_id": self.TYPE_MAP["user"]["share_id"], "oid": mid } print(f"正在为用户空间 (mid={mid}) 生成短链...") return self._post_request(data)
def generate_course(self, course_id: int, origin: str = "vinfo_player") -> Optional[str]: data = { "buvid": self.buvid, "build": self.build, "platform": self.platform, "share_channel": "COPY", "share_mode": 4, "share_id": self.TYPE_MAP["course"]["share_id"], "share_origin": origin, "oid": course_id } print(f"正在为课程 (id={course_id}) 生成短链...") return self._post_request(data)
def generate_link(self, url: str) -> Optional[str]: if not re.match(r'^https?://([\w-]+\.)*bilibili\.com/', url): print("错误:仅支持 bilibili.com 域名下的站内链接") return None data = { "buvid": self.buvid, "build": self.build, "platform": self.platform, "share_channel": "COPY", "share_mode": 4, "share_id": self.TYPE_MAP["link"]["share_id"], "oid": url } print(f"正在为站内链接生成短链: {url}") return self._post_request(data)
def main(): """命令行入口""" import argparse parser = argparse.ArgumentParser( description="Bilibili b23.tv 短链生成工具", epilog="示例:\n python b23_generator.py video 80433022\n python b23_generator.py link 'https://www.bilibili.com/video/BV1GJ411x7h7'", formatter_class=argparse.RawTextHelpFormatter
) parser.add_argument("type", choices=["video", "dynamic", "article", "collection", "user", "course", "link"], help="内容类型") parser.add_argument("id", help="内容ID或链接(视频请传aid数字)") parser.add_argument("--buvid", default="b23_generator", help="设备标识(任意非空字符串)") parser.add_argument("--build", type=int, default=7710300, help="客户端版本号(需>5520400)")
args = parser.parse_args()
generator = B23Generator(buvid=args.buvid, build=args.build)
# 根据类型调用相应方法 if args.type == "video": result = generator.generate_video(args.id) elif args.type == "dynamic": result = generator.generate_dynamic(int(args.id)) elif args.type == "article": result = generator.generate_article(int(args.id)) elif args.type == "collection": result = generator.generate_collection(int(args.id)) elif args.type == "user": result = generator.generate_user(int(args.id)) elif args.type == "course": result = generator.generate_course(int(args.id)) elif args.type == "link": result = generator.generate_link(args.id) else: result = None
if result: print(f"\n✅ 生成成功!短链: {result}") else: print("\n❌ 生成失败,请检查参数和网络")
if __name__ == "__main__": main()需要说明的是,短链接依赖服务端主动返回重定向;而本文将要分析的 ../ 路径跳转,属于浏览器对 URL 路径的自动规范化处理,下文将详细展开。
🌐URL 的演进与规范
回到诈骗链接的现场:短链跳转到的原始长链明明是类似这样的 https://www.bilibili.com/video/BV_X/../BV_Y,我们可以尝试直接在浏览器输入类似这样的网址,会发现路径中的 /BV_X/.. 消失了,是谁篡改了这个 URL—— URL路径规范化。
回顾 URL 起源与演进
1990年,蒂姆·伯纳斯·李在发明万维网时,需要一种方式标识互联网上的资源。他借鉴了当时Unix文件系统的路径表示法:
- 用
/分隔目录层级 - 用
.表示当前目录 - 用
..表示父目录
这种设计让早期开发者能够直观地理解和链接资源。比如,/docs/../images/logo.png 显然指向 /images/logo.png。在当时,这只是一个实用的约定,而非严格的标准。
随着Web的爆炸式发展,这种“野路子”带来了问题:同一个资源可以有无数个别名(如 /a/b/c 和 /a/b/../b/c),这导致缓存、爬虫和安全都面临挑战;并且,URL 的解析方式在不同浏览器、服务器间出现了分歧。例如,对 http://example.com/a/../b 的处理:
- 有的系统会直接发送原始路径
- 有的会在服务器端做规范化
- 有的甚至会把
..当作普通目录名
这导致了兼容性灾难和安全漏洞(如目录遍历攻击)。于是,互联网工程任务组(IETF)开始推动标准化。
| 时间 | 规范 | 关键贡献 |
|---|---|---|
| 1994 | RFC 1630 | 首次定义“通用资源标识符”,但只是总结现有用法 |
| 1994 | RFC 1738 | 正式定义绝对/相对URL,明确相对解析规则 |
| 1998 | RFC 2396 | URI语法独立成规范,“U”从“通用”改为“统一” |
| 2005 | RFC 3986 | 现行标准,详细定义解析、规范化、相对引用规则 |
**RFC 3986**是里程碑式的。它明确要求:任何符合标准的URI处理器,在解析路径时必须对 . 和 .. 进行规范化处理。这意味着:
- 浏览器在发送请求前,必须规范化路径
- 服务器在路由匹配前,必须规范化路径
- 任何网络库、框架在处理URL时,都必须遵循这一规则
之所以要求路径规范化,主要基于两点:
-
资源定位的唯一性
在Web中,一个资源应该只有一个规范URL。规范化确保了无论用户如何构造链接(
/a/b/../c还是/a/c),最终都指向同一资源。这对于缓存、SEO、权限控制至关重要。 -
基础安全防线
规范化是防御目录遍历攻击的第一道关卡。通过解析
..,服务器可以判断最终路径是否在Web根目录内。例如,攻击者提交../../etc/passwd,规范化后服务器能检测到目录遍历,直接拒绝请求。
规范化
显而易见的,规范化的发生在底层的基础设施,且往往不止一次:
-
浏览器端
当你在地址栏输入URL并回车时,浏览器内核在构造HTTP请求之前,就会进行路径规范化。也就是为什么我们开始在浏览器输入:
https://www.bilibili.com/video/BV_X/../BV_Y,回车,就已经是:https://www.bilibili.com/video/BV_Y -
服务器端
即使浏览器因某些原因未规范化(如构造特殊请求),请求到达诸如Nginx的服务器时,在路由匹配前同样会执行路径规范化。
-
…………
核心:. 与 .. 的处理
URL 标准有明确的规范化算法,简化后的逻辑如下:
- 初始化一个空列表
output作为规范化后的路径 - 遍历原始路径的每个 segment:
- 若 segment 为
.(或编码形式%2e)→ 跳过,不加入output - 若 segment 为
..(或编码形式%2e%2e、%2e.等)→ 若output非空,移除最后一个 segment - 否则 → 将 segment 加入
output
- 若 segment 为
以我们的链接为例:
| 原始 segment | 操作 | 当前 output |
|---|---|---|
video | 加入 | ["video"] |
BV_X | 加入 | ["video", "BV_X"] |
.. | 移除最后一个 | ["video"] |
BV_Y | 加入 | ["video", "BV_Y"] |
最终规范化后的路径为 /video/BV_Y,因此浏览器实际请求的是 https://www.bilibili.com/video/BV_Y。
示例代码 demo:
// 功能:规范化URL路径,移除 "." 和 ".."static void normalize_path(char *path) { char *p = path; char *q = path; // 核心逻辑:遍历路径段 while (*p) { if (p[0] == '.' && (p[1] == '/' || p[1] == '\0')) { p += (p[1] == '/') ? 2 : 1; // 跳过 "." } else if (p[0] == '.' && p[1] == '.' && (p[2] == '/' || p[2] == '\0')) { // 回退上一级 while (q > path && *--q != '/'); p += (p[2] == '/') ? 3 : 2; } else { // 复制普通段 while (*p && *p != '/') *q++ = *p++; if (*p == '/') *q++ = *p++; } } *q = '\0';}不止于路径
值得注意的是,URL规范化远不止处理 ..。RFC 3986及其实践通常包括以下操作:
| 操作 | 示例 | 说明 |
|---|---|---|
| Scheme转小写 | HTTP:// → http:// | 协议名不区分大小写 |
| Host转小写 | EXAMPLE.com → example.com | 域名不区分大小写 |
| 移除默认端口 | :80(HTTP)、:443(HTTPS) | 减少冗余 |
| 路径解析 | /a/./b/../c → /a/c | 移除 . 和 .. |
| 百分号解码 | %7E → ~ | 解码安全字符 |
| 移除片段标识 | #section 在发送请求时丢弃 | 片段不发送到服务器 |
示例:URI.js(JavaScript 库)的规范化
// https://www.npmjs.com/package/uri-jsconst URI = require("uri-js");let rawUrl = "HTTP://ABC.COM:80/%7Esmith/home.html";let normalized = URI.normalize(rawUrl);console.log(normalized);// 输出: "http://abc.com/~smith/home.html"// 功能:scheme/host转小写,移除默认端口80,解码安全的百分号编码结尾:回到“诈骗链接”
现在我们可以完整解释 B 站诈骗链接的机制了:
- 使用B站短链服务,将一个未规范化的 URL 生成短链接,而这个 URL 在短链服务里没有被规范化;
- 后端计算该短链接
jump_url的键值对,在解析这个未规范化的 URL 时,导致提取的是第一个BV_X的title; - 前端渲染这个
b23.tv短链,对应的title是第一个BV_X; - 点击跳转,浏览器重定向原始 URL,由于自身执行 URL 的标准化,将路径规范化为
/video/BV_Y,于是“诈骗”发生了。
所以,实际上,
https://www.bilibili.com/video/BV_X/../../后可加任意的路径(B站)。例如:https://www.bilibili.com/video/BV_X/../../opus/1035673329881579520跳转的实际上是:https://www.bilibili.com/opus/1035673329881579520。而若要解决这个“诈骗链接”问题:
- 短链接生成服务,注意对原始链接进行规范化
- 后端
jump_url的计算逻辑,注意对 URL 进行规范化
😋本文有些知识其实不需要大段论述,但实际上我就是为了这个“饺子”,才端出这个“B站诈骗链接”的“醋”喵~
相关资料
- https://www.bilibili.com/video/BV1tCw8zpE21
- https://s1.hdslb.com/bfs/seed/jinkela/commentpc/bili-comments.e0090ab8af.js
- https://www.bilitools.top/t/4
- https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Structuring_content/Creating_links
- https://sessionhu.github.io/bilibili-API-collect/
- https://en.wikipedia.org/wiki/URL
- https://en.wikipedia.org/wiki/URL_shortening
- https://url.spec.whatwg.org/#url
- https://en.wikipedia.org/wiki/Directory_traversal_attack
- https://en.wikipedia.org/wiki/Canonicalization#URL
- https://developer.mozilla.org/en/docs/Web/API/URL
NOTE笔者水平不高,若上述所言有任何错误或不合理之处,恳请见谅、加以斧正;有任何建议也欢迎提出。